Think of a Security Operations Centre (SOC) as the nerve centre of your entire cybersecurity...
CIO’s guide to Responding to an Incident in Australia

First Published:
March 9, 2026
Content Written For:
Small & Medium Businesses
Large Organisations & Infrastructure
Government
Read Similar Articles
Finding Business Continuity Planning Consultants in Australia
Engaging business continuity planning consultants is no longer a 'nice-to-have' for...
What is the NIST Cybersecurity Framework: A breakdown for Australian Organisations
So, what is the NIST Cybersecurity Framework? In simple terms, it is a voluntary set of guidelines...
Your Guide to Building a Resilient Cyber Security Strategy
A modern cyber security strategy is not a document you write once and file away. It is a living...
A Strategic Guide to NIST CSF 2.0 for Australian Leaders
Released in early 2024, NIST CSF 2.0 represents the latest evolution of a globally recognised...
When your organisation is hit with a cyber security incident, your response must be fast, decisive, and guided by a well-rehearsed plan. Fundamentally, this is not just an IT problem to solve. Instead, it is a critical business continuity process that protects your bottom line, defends your reputation, and keeps you compliant with Australian law. For Australian business leaders, effectively responding to an incident is now a core competency.
The Unforgiving Reality of Cyber Incidents in Australia

For Australian business leaders, the conversation around cyber threats has moved on. Specifically, it is no longer a question of if an incident will happen, but a stark acceptance of when. The speed and sheer number of attacks have reached a point where a purely reactive stance is a massive business risk.
The numbers do not lie. Australia's cyber security environment saw a sharp increase in malicious activity during the 2024–25 financial year. For instance, the Australian Signals Directorate's (ASD) Australian Cyber Security Centre (ACSC) was inundated with over 84,700 cybercrime reports—a new report being filed every six minutes.
To put this into context, here is a quick look at the latest statistics from the ACSC.
Australian Cyber Incident Snapshot FY2024-25
| Metric | Statistic | Year-on-Year Change |
|---|---|---|
| Total Cybercrime Reports | 84,700+ | +23% |
| Average Cost per Incident (SMBs) | $56,600 | +14% |
| Ransomware Reports | ~800 | +21% |
| Reporting Frequency | 1 every 6 minutes | -1 minute |
These figures show that the threat is not only growing but accelerating. You can get a more detailed breakdown in our analysis of the ASD Cyber Threat Report for 2025.
The Financial and Reputational Costs
For small and medium-sized enterprises (SMEs), the financial blow is particularly damaging and continues to worsen. In fact, the average self-reported cost per incident for a small business has surged by 14% to $56,600. This is not just about stolen funds; it includes the often-crippling costs of business interruption, remediation work, and the long-term hit to your reputation.
Attackers consistently go after sectors holding high-value data. These include:
- Financial Services: Targeted for direct financial theft and access to sensitive customer information.
- Healthcare: A prime target for ransomware, where criminals exploit the critical need for patient data access.
- Professional Services: Valued for the confidential client data and intellectual property they hold.
In this environment, a rehearsed incident response plan is non-negotiable. It is the difference between a controlled recovery and a chaotic freefall that could sink your entire operation.
Navigating the Regulatory Minefield
Beyond the immediate financial and operational damage, Australian organisations must contend with strict regulatory duties. For example, the Notifiable Data Breaches (NDB) scheme, managed by the Office of the Australian Information Commissioner (OAIC), requires you to report any breach likely to result in serious harm.
Getting this wrong can lead to heavy penalties and destroy customer trust. Therefore, you must build your incident response plan with your legal and compliance obligations in mind, ensuring every step you take is defensible and aligned with the law.
Ultimately, incident response has moved out of the server room and into the boardroom. It is now a fundamental pillar of business resilience and a key responsibility for every CIO, CISO, and IT leader in Australia. Consequently, the following sections will give you the actionable playbook needed to prepare for, and navigate, this challenge.
Your First Moves in Detection and Triage
The first moments after a security alert appears are where your preparation truly gets tested. How you act in this initial detection and triage phase sets the tone for everything that follows. It is the difference between a controlled response and a chaotic, expensive mess.
This is not a time for guesswork. It is about a systematic process to sort genuine threats from the noise. First, your job is to figure out if an alert is real or just another false positive from an overly sensitive system. To do that well, your team needs a rock-solid understanding of what “normal” looks like in your environment.
Establishing Clear Indicators of Compromise
Indicators of Compromise (IOCs) are the digital breadcrumbs that tell you something malicious is happening. Your security tools will throw up thousands of alerts, but your team needs to know which ones are worth dropping everything for. Getting your initial response right often comes down to having solid help desk best practices that help channel these early signals effectively.
In our experience, these are the kinds of high-confidence IOCs that demand immediate attention:
- Unusual outbound network traffic: Is data suddenly heading to an unfamiliar international IP address, especially at 2 AM on a Sunday?
- Anomalous privileged account activity: A service account that normally just runs backups is now trying to access the HR database or create a new admin user. That is a huge red flag.
- Multiple failed login attempts: A sudden storm of failed logins for one account from dozens of different locations often means a brute-force attack is underway.
- Unexpected system modifications: You are seeing core files being encrypted, new registry keys appearing, or your antivirus software has been disabled without authorisation.
Spotting these patterns fast is crucial. Speed is everything, particularly in the Australian context. For example, the ASD’s ACSC noted in its FY2024–25 findings that it proactively identified 37% of critical incidents, sending out over 1,700 notifications of malicious activity—an 83% surge from the previous year. You can read more about it in the ACSC’s Annual Cyber Threat Report.
The Critical Role of Triage
Once you have a credible alert, triage begins. This is all about assessing the severity and potential business impact to decide what to do first. For instance, a ransomware outbreak on a production server is not the same as a single laptop infected with adware, and they should not be treated with the same urgency.
A simple Triage Matrix is one of the most effective tools you can develop. It gives your team a consistent way to categorise incidents based on criteria you have already agreed on.
| Severity Level | Example Scenario | Initial Action |
|---|---|---|
| Critical | Ransomware detected on a core production database server. | Activate full incident response team, isolate the server immediately. |
| High | A senior executive’s email account is compromised. | Restrict account access, reset credentials, and analyse sent items for phishing. |
| Medium | A single endpoint is infected with known malware. | Isolate the device from the network and re-image from a clean build. |
| Low | A user reports a suspicious but blocked phishing email. | Analyse email headers and add the sender to the blocklist. |
This structured approach stops people from overreacting and makes sure your finite resources are aimed at the biggest fires first.
One of the most common mistakes we see is calling in the entire leadership team for a low-severity event. It creates unnecessary panic and pulls focus from the actual technical work that needs to get done. Your triage process needs clear escalation paths.
Effective triage hinges on one thing: visibility. A centralised logging platform like a Security Information and Event Management (SIEM) tool is not a “nice-to-have” anymore; it is essential. A SIEM pulls in logs from everywhere—servers, firewalls, endpoints, cloud services—giving you a single place to see what is going on.
For many Australian businesses, partnering with an external team for this work is a game-changer. Our guide on what Managed Detection and Response (MDR) is explains how this works in practice. In essence, it lets your internal team stay focused on strategic decisions while experts handle the 24/7 analysis, letting you respond far more quickly when an alert is real.
Containment, Eradication, and Strategic Recovery
Once you confirm a security incident is real, your focus must shift instantly to damage control. This is the containment, eradication, and recovery phase—where decisive, methodical action can dramatically reduce the financial and reputational fallout. First, the goal is to stop the bleeding. Then, you remove the threat for good and get back to business safely.
To act effectively during a cyber attack, your first moves in detection and triage are absolutely critical. Specifically, having a resilient data breach response plan guides your team through the initial chaos, ensuring a structured approach from the very beginning.
The diagram below shows the key initial steps your team needs to take.
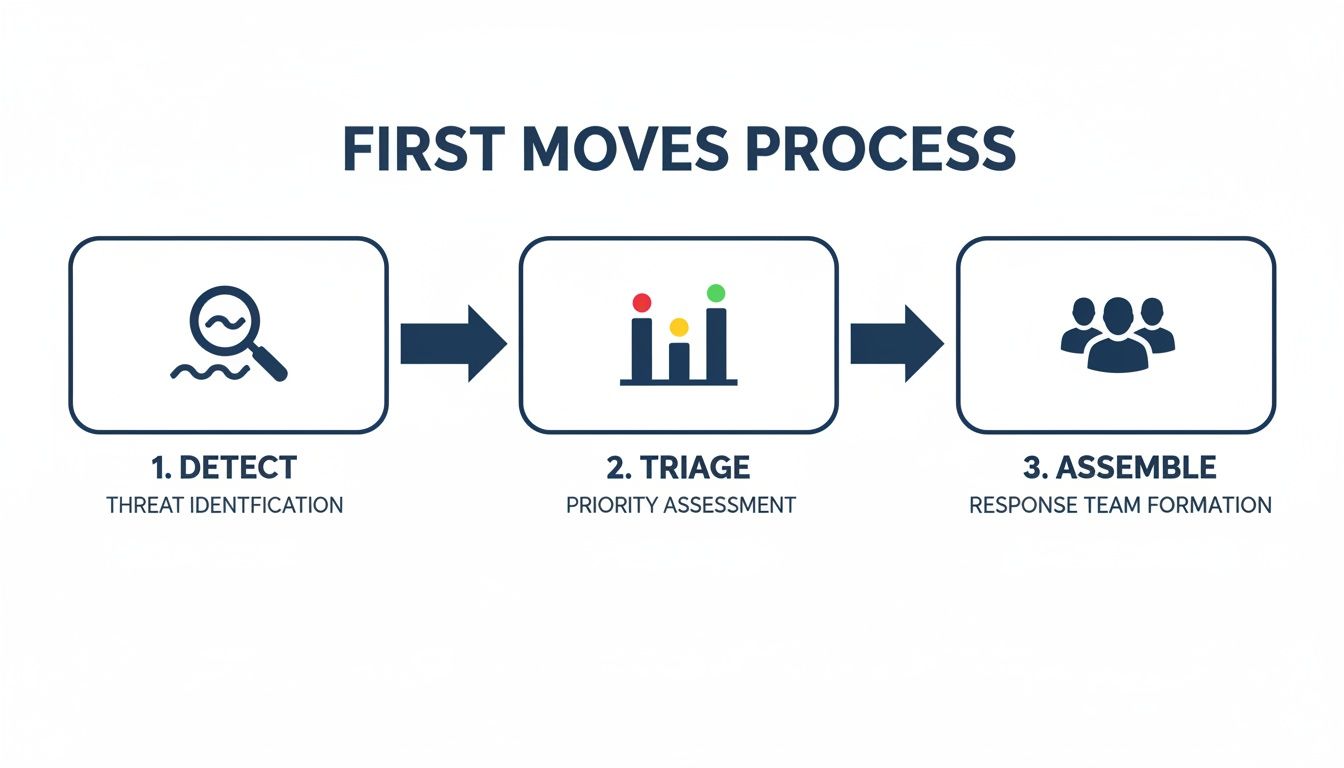
This process highlights a disciplined flow, moving from the first alert right through to assembling the right team. It is all about a coordinated response, not a panicked reaction.
Containing the Threat Without Destroying Evidence
Your first technical priority is containment: stopping the threat from spreading any further across your network. The idea is to isolate affected systems, but this must be done carefully.
Simply pulling the plug on a server might feel like a decisive fix, but you could destroy valuable forensic evidence stored in volatile memory. That evidence might be the only way to figure out how the attacker got in and what they did.
Instead, consider these containment strategies, moving from least to most disruptive:
- Network Segmentation: Use your firewall or network access controls to block traffic to and from the affected subnet or VLAN. This is often the best first move because it stops lateral movement without taking the compromised machine offline.
- Temporarily Disabling Accounts: If a specific user account has been compromised, disable it immediately. This cuts off a primary access route for the attacker.
- Isolating Individual Endpoints: You can use your endpoint detection and response (EDR) solution to quarantine a specific device. This takes it off the network while preserving its current state for analysis.
Every containment decision should be based on a quick risk assessment. Ask: what is the risk of the threat spreading versus the business impact of taking a system offline? A pre-approved containment strategy in your incident response plan removes the guesswork when you are under pressure.
Eradicating the Attacker from Your Environment
Once the threat is contained, eradication begins. This is where you methodically remove every trace of the attacker from your systems. Just deleting a malicious file is almost never enough; skilled attackers leave behind backdoors and other persistence mechanisms to regain access later.
A thorough eradication process involves a few critical actions:
- Identify and Patch the Root Cause: You must figure out the vulnerability the attacker used. Was it an unpatched server, a weak password, or a successful phishing email? Fix that entry point immediately to prevent them from walking straight back in.
- Reset All Compromised Credentials: Assume every credential on a compromised system is now in the hands of the attacker. This is not just about user passwords; it includes service account credentials, API keys, and SSH keys.
- Rebuild from a Known Good Source: Never trust a compromised system again. The only safe path forward is to wipe it and rebuild from a clean, trusted image or a backup that you know predates the incident.
Strategic Recovery and Validation
Finally, the recovery phase is all about restoring services safely and getting back to full operation. You should never rush this. Bringing a system back online without proper eradication is like leaving the door wide open for the attacker to return. Your recovery plan is a core part of what business continuity planning involves.
A strategic recovery should include:
- Phased Rollouts: Bring systems back online one by one, starting with the most critical services. This lets you monitor for any unusual activity or signs that the threat was not fully removed.
- Enhanced Monitoring: For a set period after the incident, significantly ramp up your monitoring on all recovered systems. Scrutinise logs for anything that could indicate a residual threat.
- Stakeholder Communication: Keep business leaders and department heads in the loop on your progress. Give them clear, realistic timelines for when they can expect key services to be fully restored.
By following this containment, eradication, and recovery framework, you can work through the technical side of an incident methodically. Furthermore, you will not only minimise the damage but also ensure your organisation comes out the other side more resilient.
Navigating Crisis Communications and Australian Regulations

How you communicate during a security breach can make or break your organisation’s reputation. In the high-pressure environment of responding to an incident, a clumsy message or a prolonged silence often causes more lasting damage than the breach itself. Consequently, effective communication is not just a support function; it is a strategic imperative that demands precision.
Your communications strategy will need to speak to three different audiences: your internal teams, your external stakeholders, and Australian regulators. Each group requires a carefully crafted message with a distinct tone and level of detail. Ultimately, the goal is always to project control, transparency, and empathy, while working hand-in-glove with legal counsel to avoid admitting undue liability.
Managing Internal Communications
Your own people should be your first priority. Rumours spread fast in a crisis, and an information vacuum will quickly fill with fear and speculation. A clear, controlled internal message prevents chaos and turns your team into an asset during the response.
Your initial statement to staff does not need to be long, but it must be clear.
- Acknowledge that an incident has occurred and confirm the response team is managing it.
- Direct all employees not to speak with the media or post about the situation on social media.
- Provide a single, designated point of contact for questions, typically a communications lead.
- Reassure them you are working to resolve the issue and will share updates as they become available.
This approach stops panic in its tracks and prevents well-meaning but uninformed employees from accidentally leaking damaging or inaccurate information. Furthermore, it demonstrates that leadership has the situation under control.
Crafting Your External Message
Speaking to customers, partners, and the public is a delicate balance. You must be transparent enough to maintain trust but avoid revealing technical details that could help other attackers or create legal complications. All external statements must be approved by your legal team and cyber insurance provider.
The first step is to get a prepared holding statement out the door. This is a brief, pre-approved message you can release quickly to acknowledge an incident while your technical team is still gathering facts. It buys you valuable time and shows you are taking the situation seriously.
A holding statement is not a detailed confession; it is a tool for controlling the narrative. It should confirm you are investigating a security event and are committed to protecting customers, without speculating on the cause or impact before you have confirmed facts.
As you learn more, your communications must evolve. Be clear about what happened, what information was involved, and what you are doing to help those affected. Most importantly, never make a promise you cannot keep.
Meeting Australian Regulatory Obligations
For Australian organisations, a key part of responding to an incident is complying with the Notifiable Data Breaches (NDB) scheme. This is not optional. The scheme is overseen by the Office of the Australian Information Commissioner (OAIC).
You are legally required to notify both the OAIC and affected individuals if your organisation suffers an ‘eligible data breach’. This is defined as unauthorised access to, or disclosure of, personal information that is likely to result in serious harm to one or more individuals.
From the moment you first suspect a breach may have occurred, you have a strict deadline of 30 calendar days to assess the situation and determine if you need to notify.
When assessing whether to report, you will need to consider a few key factors:
- Likelihood of Serious Harm: This assessment depends on the type of information compromised (e.g., financial details, health records), the circumstances of the breach, and the potential harm it could cause.
- Notification Content: Your statement to the OAIC and affected individuals must include your organisation’s identity, a description of the breach, the kinds of information involved, and clear recommendations on steps people can take to protect themselves.
Navigating the NDB scheme and the related Australian Privacy Principles is complex. Engaging external legal counsel with deep expertise in Australian privacy law is essential. Their guidance will help ensure your assessment and notifications are compliant, defensible, and protect your organisation from further risk.
Post-Incident Review for Continuous Improvement
The immediate fire is out and services are restored, but for resilient Australian organisations, the work of responding to an incident is not over. In fact, what comes next is often the most critical phase for building long-term security maturity.
Every single attack, whether it was contained quickly or caused major disruption, is a priceless learning opportunity. Wasting it is not an option. A structured post-incident review is what transforms a costly, high-stress event into a strategic investment in your organisation’s future resilience. Essentially, it is the process that shifts your security program from being reactive to proactive, making you a much harder target next time.
Without this crucial step, you are simply waiting for history to repeat itself, leaving the same doors open for the next attacker to walk through.
Leading a Blameless Post-Mortem
To get to the truth of what happened, you must first create a completely safe environment for discussion. This is where a blameless post-mortem becomes fundamental.
The objective is to understand the “what” and the “why” of an incident, not the “who.” When team members fear personal blame for actions they took during a chaotic and stressful event, they become far less likely to share the details needed to uncover the true root cause.
Your post-mortem should bring together everyone who played a key role in the response—technical staff, communications leads, and management. The focus must remain on a factual, collaborative reconstruction of the event timeline.
An effective post-mortem is not about assigning blame. It is about collaboratively identifying systemic weaknesses and process gaps so the entire organisation becomes stronger. Finger-pointing kills honest analysis and prevents real improvement.
Measuring What Matters: Key Response Metrics
You cannot improve what you do not measure. Gut feelings and anecdotes are not enough to track progress or justify security investments; you need hard data.
While there are dozens of metrics you could track, a few core KPIs are essential for evaluating the real-world effectiveness of your incident response capabilities.
Key performance indicators (KPIs) to track include:
- Mean Time to Detect (MTTD): How long did it take from the moment of initial compromise until your team first became aware of the threat? This is a direct measure of your organisation’s visibility and monitoring effectiveness.
- Mean Time to Acknowledge (MTTA): From the moment an alert was generated, how long did it take for an analyst to actually begin an investigation? A long MTTA can point to problems like alert fatigue, process gaps, or staffing issues.
- Mean Time to Contain (MTTC): Once the incident was confirmed, how long did it take to isolate the threat and stop it from spreading further? This KPI directly reflects the efficiency of your containment procedures and tools.
- Mean Time to Recover (MTTR): How long did it take to fully restore all affected systems and business operations back to a normal, secure state? This measures the maturity of your recovery and business continuity planning.
Tracking these metrics from one incident to the next provides a clear, evidence-based picture of how your security program is evolving. A steadily decreasing MTTD, for example, is powerful proof that your investment in new detection technologies is paying off.
Translating Lessons into Actionable Improvements
The final, and most important, output of any review is a set of concrete, actionable improvements. A post-incident report that gathers dust on a shelf is worse than useless—it is a missed opportunity.
The goal is to turn your findings into tangible changes that measurably reduce risk. A comprehensive review should identify necessary changes that feed back into your overall strategy. You can learn more about this by reviewing our guide to building a computer incident response plan.
These actions typically fall into three main categories:
- Process and Plan Updates: Was a critical step missed in the incident response plan? Was an escalation path unclear or incorrect? Your plan is a living document; therefore, it must be updated with the lessons you have just learned the hard way.
- Control and Technology Enhancements: Did the incident expose a clear gap in your defences? Perhaps it revealed the need for better email filtering, more advanced endpoint protection, or stricter alignment with the ASD Essential 8 maturity levels.
- People and Training Adjustments: Did team members struggle to use a particular tool or follow a specific procedure under pressure? The incident may highlight a clear need for targeted training, like running more phishing simulations or holding practical drills on containment protocols.
Incident Response Compliance Checklist for Australian Businesses
Aligning your incident response plan with key compliance frameworks is not just a box-ticking exercise; it ensures your processes meet established best practices and regulatory expectations. For Australian organisations, this often means mapping activities to standards like ISO 27001, SOC 2, and the ASD Essential 8.
The table below provides a high-level checklist to help you align your IR processes with these key standards.
| Compliance Framework | Key Incident Response Requirement | CyberPulse Solution |
|---|---|---|
| ISO 27001 | Requires a formal information security incident management process, including defined roles, responsibilities, and procedures for response, communication, and learning from incidents (Annex A.5.24 – A.5.28). | Our incident response playbook templates are designed to meet ISO 27001 requirements for planning, response, and post-incident review, supporting your ISMS certification. |
| SOC 2 | The Security (Common Criteria) principle requires procedures to detect, respond to, and recover from security incidents. Auditors test the design and operating effectiveness of these controls (CC7.3). | We help you document and test your incident response controls, providing the evidence needed for a clean SOC 2 Type 2 attestation report. |
| PCI-DSS | Requirement 12.10 mandates a comprehensive incident response plan that is tested at least annually. It specifies roles, communication strategies, and procedures for handling payment card data breaches. | Our PCI-DSS-specific IR templates ensure your plan meets all 12.10 sub-requirements, including alert monitoring, evidence handling, and coordination with payment brands. |
| IRAP / ASD Essential 8 | Requires robust incident detection and response capabilities, particularly around Maturity Level 3 of the Essential Eight, which focuses on timely detection, analysis, containment, and eradication of threats. | Our services help you implement and mature your Essential Eight controls, providing the IRAP assessor with clear evidence of your capability to manage incidents affecting government data. |
Using this checklist helps ensure that when an incident occurs, your response is not only effective but also demonstrably compliant. This strengthens your position with regulators, customers, and partners alike.
Your Incident Response Questions, Answered
When you build out a defence strategy, it is natural for questions to appear about what to do when things go wrong. As Australian CIOs, CISOs, and IT Managers plan for the worst, we see the same queries come up time and again. Here are straight-to-the-point answers to the questions we hear most often about incident management, compliance, and getting prepared.
I Suspect a Data Breach. What Are the First Three Things I Do?
First, activate your incident response team. Whatever you do, do not try to handle it alone. A chaotic, solo response almost always leads to mistakes and can destroy critical evidence. Following a pre-agreed plan brings structure from the very first minute.
Next, focus on containment. Your immediate priority is to isolate the affected systems from the rest of the network. This one move is the most critical action you can take to stop the threat from spreading deeper into your environment.
Finally, start documenting everything. Create a running log with timestamps for every action you take, every system you touch, and every piece of information you uncover. This log will become invaluable for your investigation and for meeting your obligations under Australia's NDB scheme.
How Do I Know if a Breach Needs to Be Reported to the OAIC?
Under the Notifiable Data Breaches (NDB) scheme, you must notify the Office of the Australian Information Commissioner (OAIC) and the affected individuals if an 'eligible data breach' happens. This is defined as a breach where personal information is accessed without authorisation and is likely to result in serious harm.
You have a legal requirement to carry out a swift assessment, which you must complete within 30 days, to figure out if that "serious harm" threshold has been met.
We strongly advise engaging legal counsel to help with this assessment. Their expertise is crucial for correctly interpreting the 'serious harm' threshold and ensuring your notification process is fully compliant, protecting your organisation from further regulatory risk.
If your assessment finds that serious harm is likely, then reporting it is mandatory.
Can We Just Rely on Our Cyber Insurance Instead of an IR Plan?
No, and this is a dangerously common misconception. Cyber insurance is a financial tool, designed to help cover the costs after an incident has already happened. It is not a substitute for an incident response plan.
In fact, most insurers now require organisations to have a mature incident response plan and prove a strong security posture just to qualify for a policy. This often includes showing you are aligned with the ASD Essential 8. Your plan dictates the actions that shrink the scope and impact of an attack, which in turn can lower your insurance claim and future premiums.
What Role Does the ASD Essential 8 Play During an Incident?
The ASD Essential 8 is primarily a set of proactive strategies meant to stop most cyber attacks before they can even get started. That said, they play a surprisingly important role during an active incident response as well.
Their influence on a live response includes:
- Stopping Threat Execution: If you have application control properly configured, it can prevent malware from running even if an attacker manages to get it onto one of your systems.
- Blocking Lateral Movement: Properly implemented multi-factor authentication makes it significantly harder for attackers to use stolen credentials to move across your network or get back in after you have kicked them out.
- Making Eradication Simpler: A network built on the Essential 8 framework is just a more defensible and predictable environment. This simplifies the containment and eradication phases because there are far fewer avenues for an attacker to hide or exploit.
Ultimately, having the Essential 8 in place demonstrates due diligence. It proves to regulators and insurers that you have taken reasonable and recognised steps to protect your organisation.
Ready to move from a reactive posture to a proactive, resilient defence? The experts at CyberPulse can help you build and test an incident response plan that aligns with Australian regulations and protects your business. Fortify your security by visiting us at https://www.cyberpulse.com.au.
Browse to Read Our Most Recent Articles & Blogs
Subscribe for Early Access to Our Latest Articles & Resources
Connect with us on Social Media
